The Shapes of Stories with ChatGPT
Investigating classic literature with a Large Language Model
View on SubstackThere’s no reason why the simple shapes of stories can’t be fed into computers. They have beautiful shapes.
—Kurt Vonnegut
Years ago, I saw a video of Kurt Vonnegut drawing the shapes of stories on a blackboard, and was fascinated:
tl;dw—Vonnegut plots the well-being of characters over time, and claims that there are a few basic sine-wave-esque shapes that emerge over and over. You can also check out the extended version.
I’ve always wanted to test this claim empirically, but struggled to do so. Old-school NLP tools (like sentiment analysis and named entity recognition) don’t seem to be up to the task, for reasons I’ll explain below. Fortunately, LLMs like ChatGPT are far more sophisticated!
I used the ChatGPT API to get ratings for the well-being of characters in a few dozen works of classic fiction. You can play with interactive graphs of the data, or keep reading to learn how they were made. You can also jump down to the Results section of this post to see the highlights.

Outline
Initial Failures
Before we get into the ChatGPT methodology, let’s talk about some less sophisticated strategies.
In my first attempt, I ran sentiment analysis on each passage of the text. A very naive sentiment analysis algorithm will simply look for words like “good”, “bad”, “happy”, “terrible”, etc. and provide an overall score. More sophisticated methods can take things like negation or sarcasm into account.
But even the most sophisticated sentiment analysis doesn’t get us very far. The sentiment of a passage doesn’t necessarily correlate with the main character’s fortune—the book might be told by a matter-of-fact narrator, or the villain’s lines (which have the opposite sentiment to our target) might confuse the algorithm. And sentiment is always relative: a passage where a despairing character finds a ray of hope might be classified as very high sentiment, even though their overall fortune is only slightly above rock bottom.
When I actually tried this, the graphs mostly looked like regular sine waves—there seems to be a natural heartbeat of positive and negative tone in novels.
I tried to improve on this by using named entity recognition (NER), and only scoring passages where the main character appears. This improves things slightly, but is still prone to all the issues above.
Enter LLMs
LLMs are far more sophisticated than any of the items in your classic NLP toolkit.
Given a chunk of text, you can ask the LLM anything about it. That includes classic NLP tasks like part-of-speech detection, summarization, and sentiment analysis. But it can also do more interesting things, like imagining what might happen next in the story. And it can provide the reasoning behind its conclusions.

Importantly, we can give an LLM a passage from a story, and ask it how the characters feel!

Of course, we don’t just want a high-level explanation of the character’s feelings—we want some structured data. Specifically, we need a number that can help us quantify the net valence of their feelings. We’ll talk about how to construct a more useful prompt below.
Methodology
Source Data
I started by downloading a few dozen of the top books on Project Gutenberg.
Unfortunately, we can’t feed ChatGPT an entire novel at once. The basic tier only offers a window of 4096 tokens—about twice the length of this blog post. But ChatGPT seems to be very familiar with these stories, so it has a lot of the context it needs. And we’re only interested in examining one passage at a time, so this shouldn’t hurt us too much.
I chunked up each text into blocks of 10,000 characters, which is well below the window limit. This yields as few as 17 chunks for a small text like Alices Adventures in Wonderland, but 335 chunks for War and Piece. Each of these chunks will become a data point in our graphs.
Main Characters
The next step was to determine the main characters in each book. I limited myself to four, which is sometimes too many (do we really need to know how baby Pearl feels in The Scarlet Letter?) and sometimes not enough (I was disappointed to miss Smerdyakov in The Brothers Karamazov).
Previously, I’d tried to solve this task using NER and finding the most common names. But since we’re studying classics, and ChatGPT has pretty great world-knowledge, we can just ask it!
Who are the four most important characters in %s by %s? Please respond in CSV format, with no other text (Annoyingly, ChatGPT did not always respect CSV format. The responses took a lot of cleaning up.)
Prompt Engineering
For each chunk of text, we need to ask ChatGPT how the characters feel. We also need to tell it to reply in a structured format, so we can parse the results properly.
Here’s the prompt I eventually settled on:
Let's read %s by %s together. We're %d percent of the way through the book. Here is the section we're reading:
<10,000 characters of text>
On a scale of 1-9, with 1 being terrible, 5 being neutral, and 9 being extremely happy, how do you think the following characters feel at the end of this section of the story? Please respond with the name of each character on a new line, followed by a colon, then the number. Write only a single number. Only use whole numbers, no fractions like 6.5. If you can't determine a good answer, or if the character is not mentioned in this part of the story, respond with 'N/A' instead of a number. To the right of the number, add a hyphen, and describe your reasoning in a single sentence.
The characters you will judge are:
* <Character 1>
* <Character 2>
* <Character 3>
* <Character 4>You can tell from the prompt that this took some iterating. I had to be very explicit about the structure and the sort of data I want back. Even with all that, about 1% of responses have to be discarded due to a parsing error of some kind.
Here’s a typical response:
Alice: 5 - Alice's feelings are not explicitly described, but she is curious and intrigued by the Wonderland she has stumbled upon.
White Rabbit: 7 - The White Rabbit seems anxious and in a hurry, but ultimately seems relieved to have evaded Alice's pursuit.
Queen of Hearts: N/A - The Queen of Hearts does not make an appearance in this section of the story.
Mad Hatter: N/A - The Mad Hatter does not make an appearance in this section of the story.The answers aren’t always perfect. Above, I’d probably have rated the White Rabbit as a 3 or 4, given that all we know is he’s late and agitated about it.
To help smooth things out, I ran three trials for each passage, and took the median result (if any of the results were “N/A”, that was the final rating). I found the median works a bit better than the average, because it helps discount one-off outliers. With more trials, average probably would have worked better.
Image Generation
To help present the data, I decided to ask DALL-E to generate a sketch for each character. A simple prompt like this works surprisingly well:
a detailed colored pencil drawing of %s from the book %s by %s.DALL-E seems to have enough world-knowledge to know that Moby Dick characters are sailors, and that Dickens characters should be in Victorian dress. But it gets some characters pretty wrong. Here’s Queequeg from Moby Dick:

But ChatGPT can rescue us! We can ask ChatGPT—which again, is very familiar with these stories—for a physical description of each character, then feed that description into DALL-E. Here’s what we get back for Queequeg:
Describe the physical appearance of Queequeg in the book Moby Dick by Herman Melville.
Queequeg is a tall, burly man with dark skin, curly hair, and a heavy beard. He has a tattooed face with intricate designs and carries a shrunken head on a cord around his neck. He wears a brightly colored headdress made of feathers and a girdle of painted shells around his waist. His muscular arms are adorned with bracelets, and he carries a carved wooden idol named Yojo with him everywhere he goes. Overall, Queequeg's appearance is exotic and striking, reflecting his Polynesian heritage.Which results in this image

Much better! Not perfect (compare to typical depictions), and a little trippy with that beard-stache, but decidedly human.
(Another fun issue with DALL-E: it refuses to draw any prompt containing the word “dick”. I had to bowdlerize the Melville prompts, and even “Edward Prendick” from The Island of Doctor Moreau. You’d think an AI company could do a better job here.)
Presenting the Data
As you’ll see below, ChatGPT’s answers are pretty spiky. It’s still prone to the same recency-bias as sentiment analysis, where it puts a lot of weight on relative changes in fortune, rather than the character’s overall state (though this might be a feature, not a bug).
To help smooth things out, I overlaid each graph with a moving average, which hides a lot of the noise.
One issue with this: frequently there’s a huge swing in fortune at the beginning and end of a story. This confuses the weighted average, which shows the character ending up in a mediocre state, because it doesn’t want to weight that final data point too heavily. To fix this, I pinned the ends of the weighted average to the actual data.
There are also times where a character isn’t present for a large portion of the text. In this case, I preserved their most recent rating, or rated them neutral if they hadn’t appeared yet.
Results
I’m really happy with the results for some stories.
Romeo and Juliet is one of the cleanest examples, probably because it’s short and the emotional content is clear-cut. I love how neatly their graphs line up:

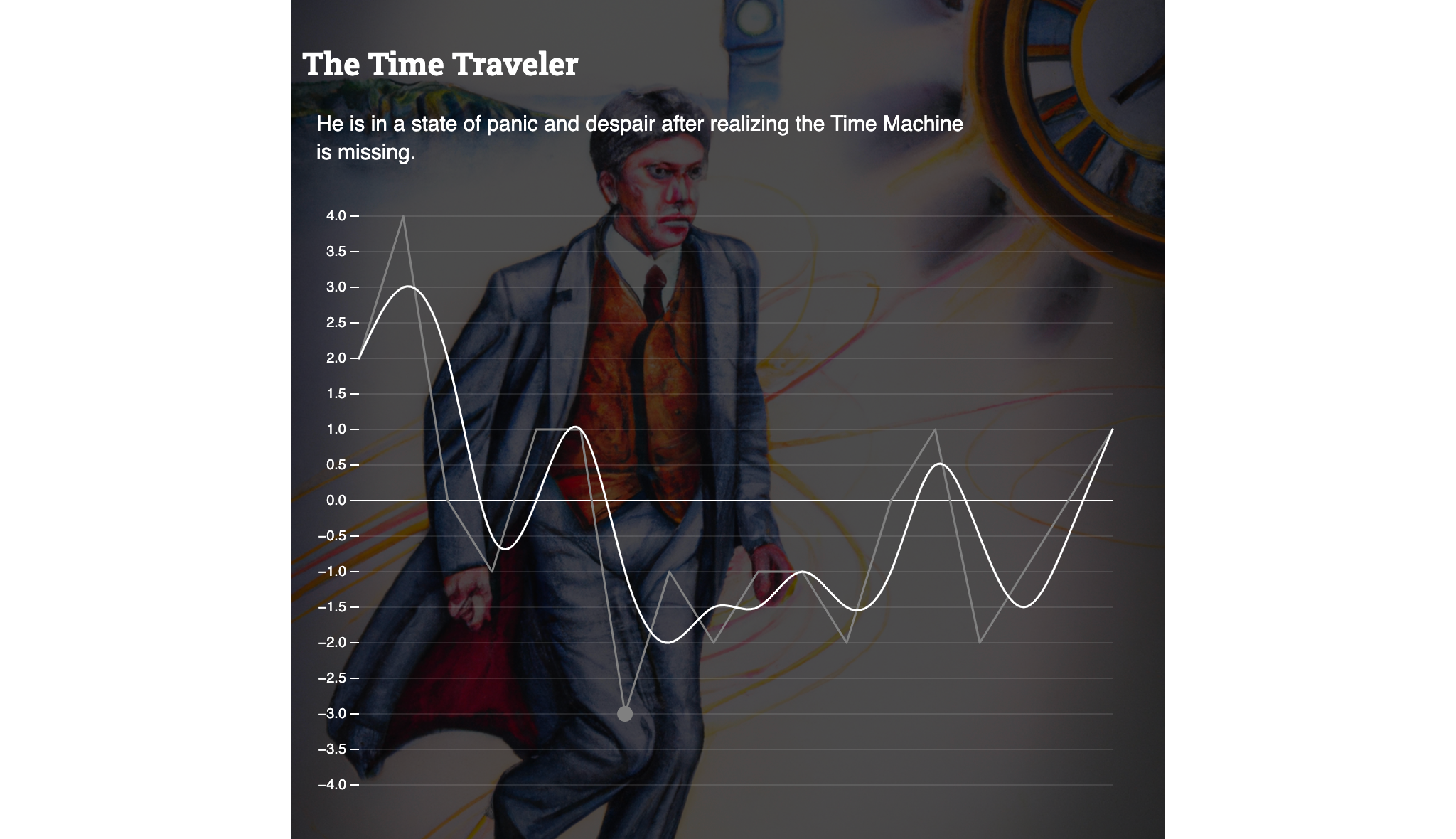
The best example of Vonnegut’s “man in a hole” scenario is probably H.G. Wells The Time Machine:
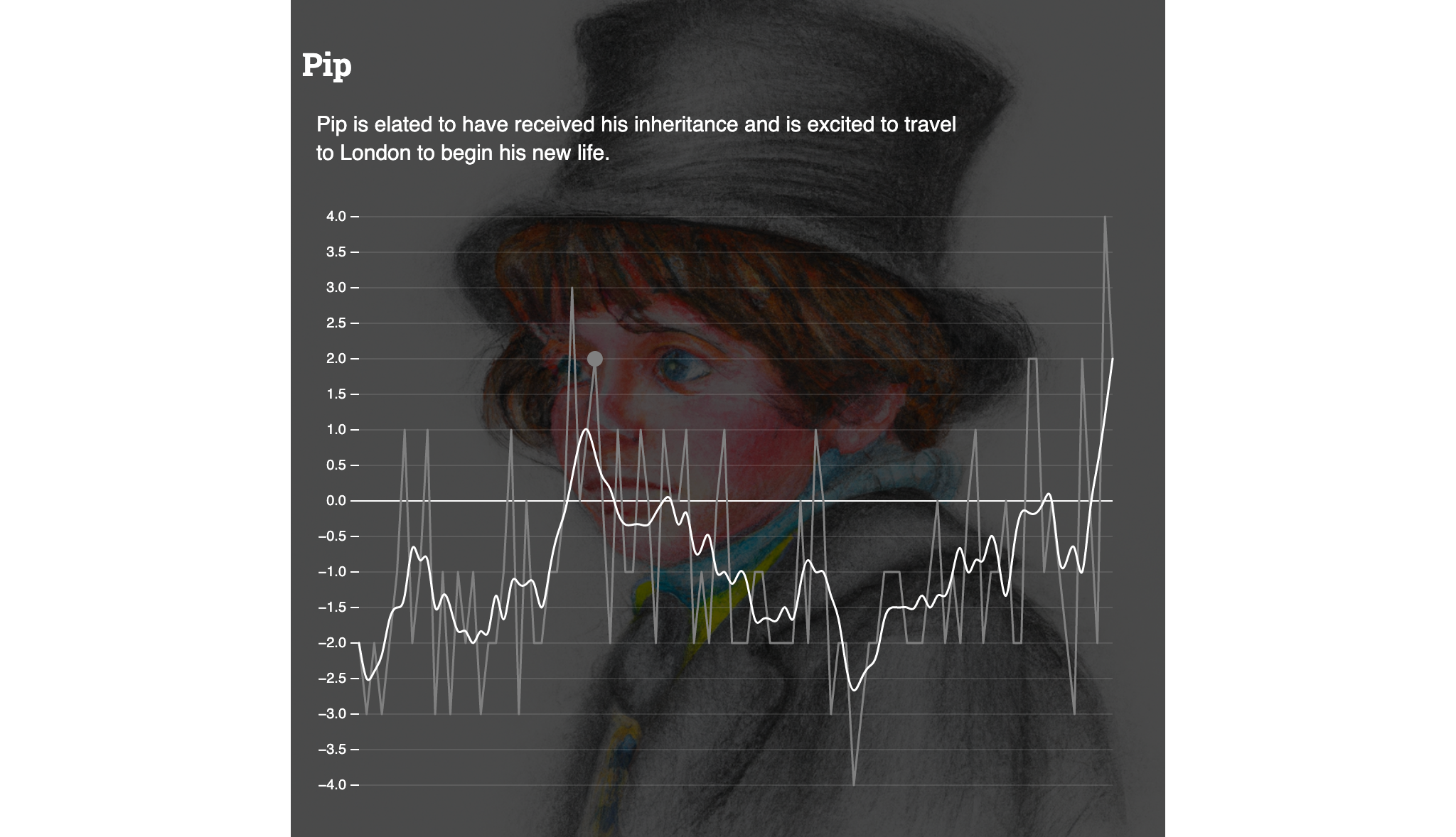
Pip’s trajectory in Great Expectations seems to follow Vonnegut’s “boy meets girl” scenario (find something great, lose it, get it back):
And Gregor Samsa’s fate is much how Vonnegut describes it in the extended video:

Vonnegut’s description of Hamlet’s story—where none of the events, no matter how extreme, have much of an impact on his well-being—was more on-the-nose than I expected.

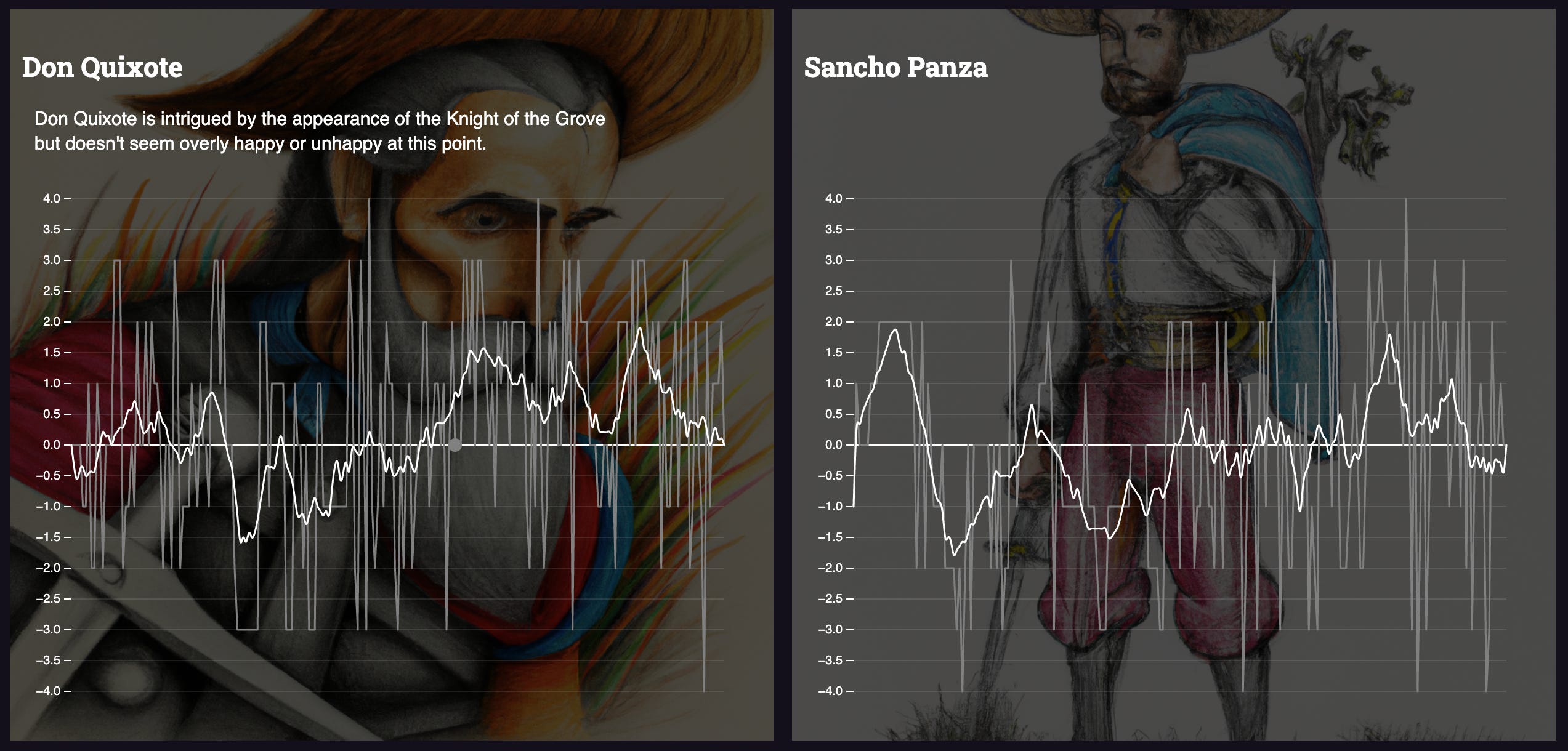
But a lot of the books I tested have less interesting results. E.g. Don Quixote and Sancho Panza just bop around randomly throughout their adventures. This fits my memory of the book as well.
Limitations and Future Work
There’s a lot we could do to continue improving here.
The prompt itself could use some work. I asked “how do you think the following characters feel”—but asking about “fortune” or “well-being” might be truer to Vonnegut’s theory.
There’s also the window-size problem—being able to feed the entire novel into ChatGPT as context would likely help. And my strategy of feeding it 10k characters at a time is pretty naive—e.g. it definitely cuts words in half. I didn’t spend much time tuning this.
An interesting question is how this process would perform on a novel it’s never seen before. With only a small window of context, it would probably miss a lot of the nuance related to the characters’ history. And it’s unclear how much ChatGPT might be relying on its knowledge of literary criticism or Reddit threads when analyzing classics.
I used ChatGPT-3.5, which has since been superseded by ChatGPT-4. I suspect the results will get more accurate with an upgrade—version 4 allegedly has an improved theory of mind. We might even be able to get away with only a single trial per passage, which would speed up the pipeline and reduce costs.
Speaking of time and cost: I spent $120 and a couple days on this project. Running the entire pipeline end-to-end for all books takes about 10 hours, and probably costs ~$30.
Lessons
Honestly I’m amazed at how much I was able to do with ChatGPT. It’s much more than a toy chatbot. It’s a mechanical turk, minus the turk.
I could have done this project with humans for a lot more time and money—just pay a bunch of people to read novels and perform the same ratings. I’d also need to hire an artist to do dozens of drawings.
My back of the envelope math says I could get it done for $8,500. The fact that I can now do the same thing for tens of dollars is unreal—for this very specific task it improves productivity by 200x.
People are fretting about all the jobs that will get sucked up by AI (a legitimate concern), but I’m much more excited about all the things we never thought were worth doing, simply because they’d take too many people-hours.
Working with LLMs is like having an army of undergraduate interns at your disposal. Sure, they’re a little goofy and make some stupid mistakes, but with explicit instructions and plenty of oversight, they can do incredible work.
I’m very excited to see what we build.
Check out the demo and let me know what you find in the comments!
10 comments on Substack. Join the discussion!