The Future of Art is Artificial
AI will enable creative people to do amazing things
View on SubstackAI-generated media has quite suddenly leapt from quirky and error-prone to novel and compelling. With the public release of Stable Diffusion, I think it’s worth taking a look at how AI is going to invigorate creative professions in the coming years.
When a new technology emerges, it’s natural to lament the disruption and loss of skills it will inevitably bring. But there are also plenty of reasons to be excited: AI will enable a new tranche of creators to begin expressing themselves, and allow innovative professionals to create experiences that would have previously been impossible.
I think we’re in the first inning of this transformation. Let’s look at ways AI might enhance our creativity.
Outline
Principles of Creation
Creation vs Discovery
Creative Technologies
Exploring Vector Spaces with AI
Autoencoders
Style Transfer
Fill-in-the-Blank
Human-Computer Interfaces
Iterative Prompts
Domain Modeling
Compute
Transforming Media
Principles of Creation
Before we get started, we’ll need to talk a bit about the creative process, so we can see how AI fits in.
Creation vs Discovery
The sculpture is already complete within the marble block, before I start my work. It is already there, I just have to chisel away the superfluous material.
- not Michelangelo
There’s a fuzzy boundary between creation and discovery. Were computers created or discovered? To me, the abstract concept of turing machines exists in some Platonic mathematical space, waiting to be discovered; silicon transistors, on the other hand, seem like a fairly arbitrary configuration of matter that had to be invented, i.e. created. But it’s hard to justify this distinction on first principles.
For a real mindfuck, consider the fact that there are only a finite number of images that can fit on your computer screen. A two-line computer program can enumerate every possible image, independently creating the Mona Lisa, every photo of your kids, every Looney Tunes cel, literally everything. You’ll often hear this referred to as “image-space,” or more abstractly, a “vector space.”
A creator’s job is to explore this space.
Of course, it’s a huge space. Even with strict constraints, like only black-and-white 1 megapixel images, would have something like 2^1000000 images, which Duck Duck Go tells me is equal to infinity. There’s probably not enough time left in the universe for our program to finish.
It’s also a space filled with mostly boring images. Pick a spot at random, and you’re almost guaranteed to see static.

But under the hood, all creation is an act of discovery. When we say that painting is a creative endeavor, we mean that you can’t just bumble around in image-space hoping to discover an island of beauty. You have to have a clear vision for where you’re going and how you’re going to get there. Non-creative discovery is much easier—Christopher Columbus just had to point west and go forward.
The same goes for novels, music, movies, video games, etc. Human experience is bounded by finite time, space, and resolution, but there’s still a heck of a lot to explore.
Creative Technologies
Now that we’re used to thinking of art in terms of vector spaces, we can talk about how tech fits in.
Creative technology helps by making exploration easier—it makes the act of creation feel more like discovery. There are thousands of ways to help navigate huge spaces, but here are a few common patterns:
You can bound the space, weeding out a lot of static
E.g. tonal instruments provide a specific set of curated notes, instead of the full range of frequencies you can sing
You can project a large space onto a smaller space, which can be more easily explored
E.g. an arpeggiator can take a single frequency and generate a much more complex sound
You can enable the exploration of nearby points in space, once you’ve found a good one
E.g. Photoshop can take an image and produce millions of “nearby” images, some of which look better
The wonderful thing about AI is that it’s really good at exploring gigantic vector spaces. That’s literally all Deep Learning is—finding ways to explore, map, and constrain very large vector spaces.
Exploring Vector Spaces with AI
If we’re going to talk about exploring vector spaces, there are a few AI-related concepts you should know about.
Autoencoders
Autoencoders are automatic compression algorithms. They can take a giant space, like our image-space above, and cut it down to something much smaller.
Of course, there’s no free lunch when it comes to compression. An autoencoder has to target a particular subspace, like pictures of hotdogs or handwritten numbers. If the autoencoder is successful, you get a really nice low-dimensional space for exploring your domain.
Here’s an amazing paper that creates a 2D space for exploring handwritten digits using an autoencoder. The results are beautiful:
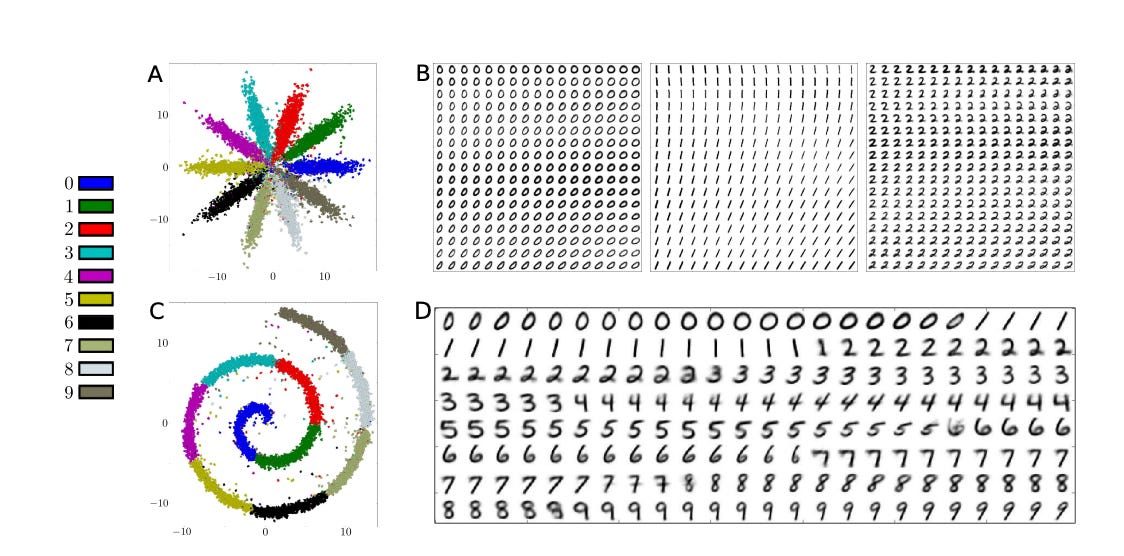
In the example above, each point on the plane corresponds to an image; blue dots correspond to images that are labeled “0,” green dots correspond to “1”s, etc. The points in the corners, far away from any color, probably represent static.
This covers two of our strategies for exploring a large vector space:
It projects a large space onto a much smaller (i.e. lower dimensional) space, which is easier to explore
It makes it easy to take an image and explore nearby images—e.g. I can draw a “2,” find its spot in the plane, and move around a bit to find similar-looking “2”s.
Style Transfer
Style transfer constellates a small volume in your vector space, and allows you to map all sorts of things onto it.
For example, we might start by defining a tiny corner of image-space, like “Vincent van Gogh paintings.” Style transfer allows us to ask questions like, “What if van Gogh painted the Mona Lisa?”
Hypothetically we can give our style transfer algorithm any image, and it will map it onto the comparably tiny space of “Vincent Van Gogh paintings.”

Note that this isn’t limited to imitating individual artists. You could pick a specific era, brush stroke technique, color composition, whatever. You just have to give the algorithm a set of target images that define your domain, and it’ll do it’s best to map other images nearby.
Fill-in-the-Blank
Fill-in-the-blank problems define a volume in the vector space, and ask the AI to find “likely” points within that volume. For example, we might give an AI algorithm an image with a piece missing, and let it guess at how to fill it in:

What’s “likely” is determined by the other data the algorithm has been trained on. If it’s only ever seen pictures of cats, it will probably try and put some whiskers in there.
Human-Computer Interfaces
So where’s the low-hanging fruit in building AI for creative professionals? Most of it comes down to understanding natural language.
Natural language is the holy grail of interfaces. Currently we have to bend to our machines—we speak to them hunched over keyboards, dragging cursors around on screens, interacting in an esoteric and unforgiving “language.” You clicked the wrong button? Sorry, you’ll need to fill out the entire form again.
Perfect, human-level natural language understanding will feel like having an army of semi-skilled interns in your pocket. But we’ll need a few things before we get there.
Iterative Prompts
The latest algorithms can understand single, specific commands really well. “A pencil drawing of an astronaut riding a horse” or “Who won the World Series in 1995?” or “How do I get to Carnegie Hall?” are all well within reach for contemporary algorithms.
But they’re still lacking when it comes to iterative tasks. I can’t ask for my pencil drawing of an astronaut riding a horse, then ask for a bigger horse, fewer pencil marks, oh and please add Saturn in the background.
We could construct one giant prompt with all of this information, but that’s not as helpful. Each time I go back to my prompt to add more information, the previous prompt is forgotten, as well as the image it generated. Maybe I was very happy with my astronaut, and just wanted a slightly bigger horse.
DALL-E can kind of do this. You can erase an area of your picture, and rephrase your entire prompt. The results aren’t terrible, but also not great. Currently, the creative loop consists of prompt → photo editing → prompt → photo editing → prompt, instead of just prompt → prompt → prompt.
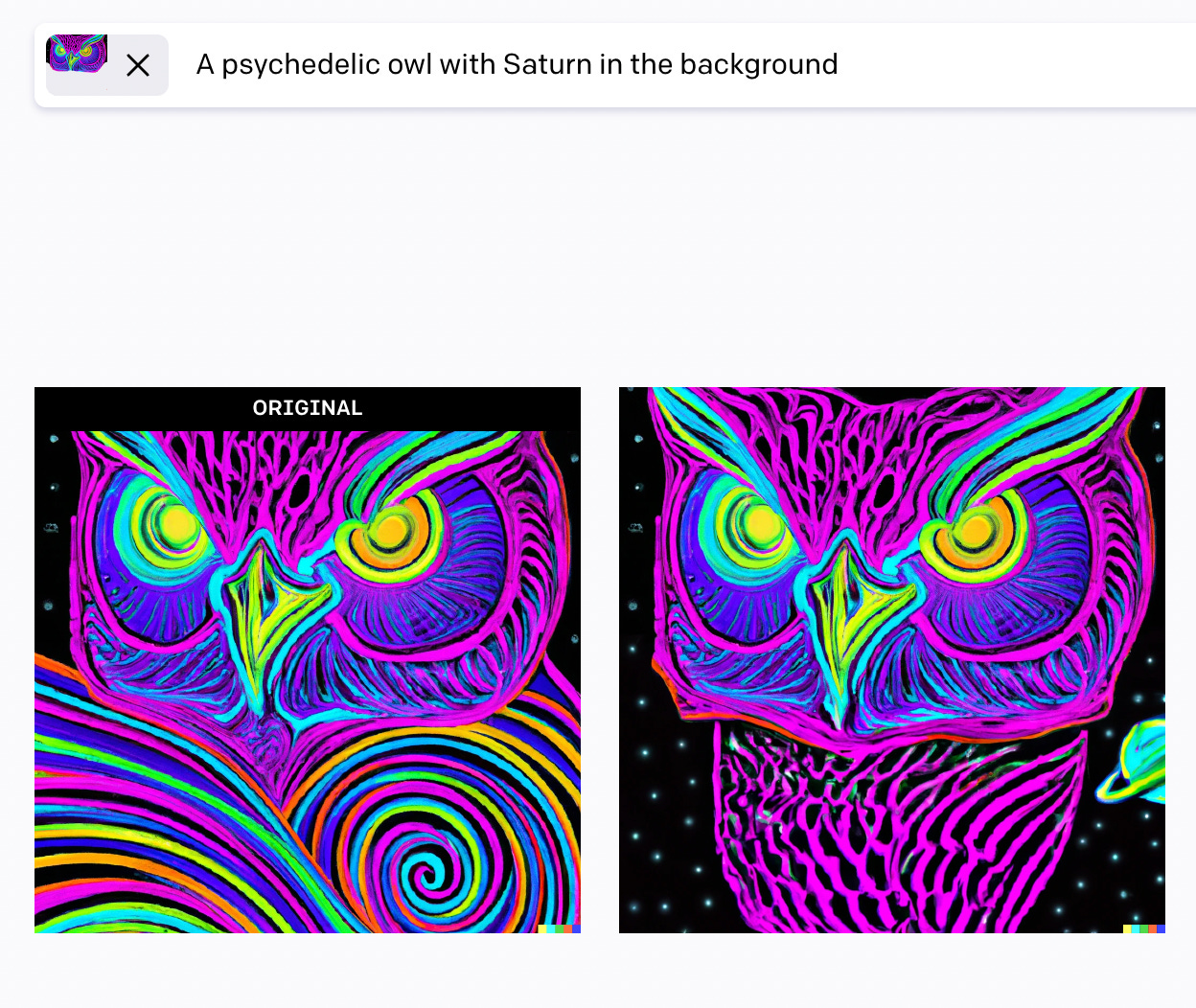
An iterative method allows us to quickly find a desired volume in the vastness of image-space (e.g. astronauts riding horses) and then slowly explore that area, honing in on exactly what we want. If instead I’m forced to revise my initial prompt, the AI starts again from scratch, and we end up with a big jump in image-space, which is jarring.
The next wave of AI-based creativity will need to see huge progress in iterative prompts. That will enable an entire process to develop around AI-generated art, and it will feel more like a collaborative exercise, as opposed to the one-off call and response we get today.
Domain Modeling
A big part of improving iterative prompting will mean deeper domain-specific understanding. The prompt “stronger” means something very different for a picture of a man, a picture of a bridge, a speech about human rights, or a guitar riff.
DALL-E and GPT-3 seem to do an incredible amount of domain modeling already, just from having seen lots of data. It’s an open question whether engineers will need to hack in a little domain knowledge, or if further advances will just need more data. I lean towards the former, but I’ve always leaned in that direction, only to be surprised by a general model working on a huge dataset.
A good example here is text in DALL-E-generated images.

There’s some amazing domain understanding here! Tell me that’s not George Clinton with the big rainbow hat.
But DALL-E completely flubs the text. It draws mostly English-looking letters, and even reasonable syllables. It even seems to get that the band name should start with an “F”. But I doubt even Funkadelic would release an album called “Fackel Findunle.”
There’s enough progress here that it’s tempting to think we just need more data. But surely it’d be easier to wire in GPT-3 to bring in a huge amount of text-domain knowledge?

The words “wire-in” are doing a lot of work there, but you see where I’m going. Trying to re-learn English by looking only at text embedded in images is probably doable, but it’s not the most elegant solution to the problem.
Compute
Finally, if we’re going to make AI a part of the creative process, we need it to be faster and cheaper.
Currently it takes about 10-15 seconds to generate an image with DALL-E, and costs about $0.13 per prompt. For basic tasks like generating a logo for your blog, this is perfectly reasonable.
But for ambitious art projects, this could be prohibitively expensive and time-consuming, especially if we start thinking about video. An hour of footage, at 30 FPS, would cost around $14,000 and take 300 hours of compute. And that’s just for the final production! Never mind all the frames that get generated and thrown out during the creative process. The true cost would easily be an order of magnitude higher.
To fully enable AI-centric creation, we’ll need rapid feedback—say, 1-2 seconds per prompt. And we’ll need the ability to explore and prototype without worrying about the cost. Better ways to deploy these models on local hardware would be a huge help here, since it would eliminate the marginal cost of each prompt, and artists could scale up their rig for faster generation. This is why I’m so excited for the public release of Stable Diffusion.
Transforming Media
I wanted to talk a lot more about how AI-based tools will transform specific industries, like art, television, music, and writing. But this is already a long article and it’s late. If you’re interested in reading part two, you know what to do.
Related

Join the discussion on Substack!